Posture management has turned into an exercise in prioritization, but this hasn’t made us safer.
This post was written by Chen Burshan, CEO of Skyhawk Security
If a Tree Falls in the Forest…
We all know the adage, “If a tree falls in the forest and nobody is there to hear it, does it make a sound?” It’s a philosophical allegory essentially questioning whether something that has not been empirically seen or heard has importance or consequence.
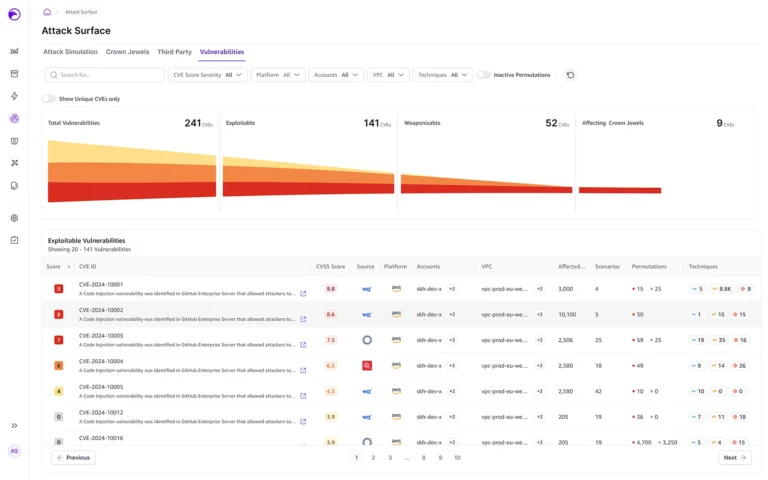
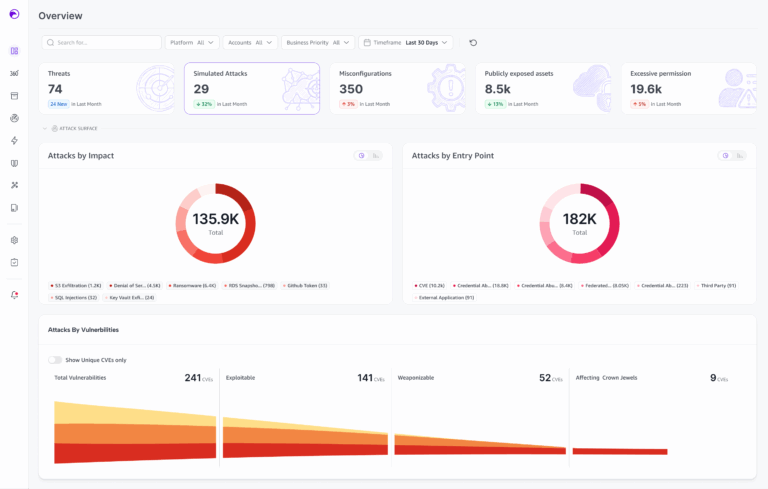
In security, and particularly cloud security where Skyhawk has gathered some expertise, this allegory is the fundamental question to ask about alerts that come from popular security posture management tools. Notifications on misconfigurations, vulnerabilities, and combinations of the two are abundant but are not always toxic unless they can be exploited by threat actors. Like those trees in the forest, they do make a sound, but the sound they make is irrelevant. Alerts on misconfigurations are no different. How significant is any one misconfiguration alert? 99% of the time, not significant at all.
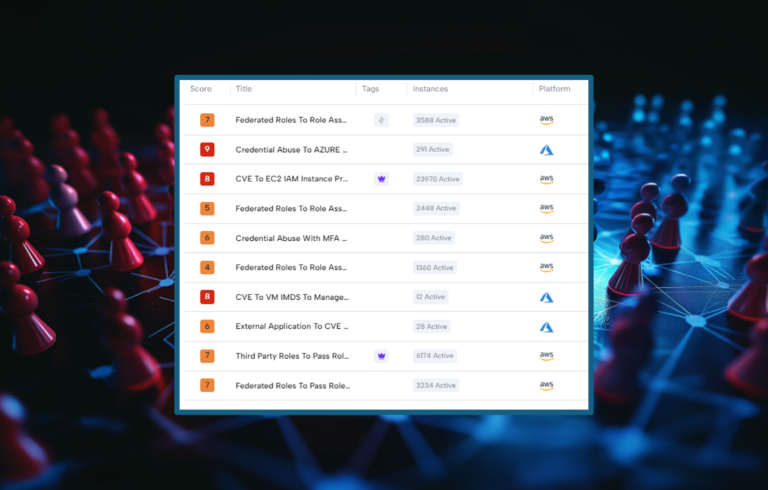
For this reason, as the cloud security landscape matured, vendors began to apply ‘attack graphs’ or to refer to a series of static misconfigurations and vulnerabilities as ‘toxic combinations’ that could be used by an attacker to infiltrate cloud infrastructure. Instead of many individual insignificant alerts, static misconfigurations and vulnerabilities were grouped and correlated together in ways that showed how a potential threat actor could make use of a few static misconfigurations and vulnerabilities together. This could enable DevOps / DevSecOps teams to prioritize alerts that seemingly had more potential to threaten an environment.
But prioritization was still not enough. In fact, prioritization only amplified the need for something better. Because even if you prioritize and fix the top five posture issues, you leave the rest below the DevSecOps attention threshold. By design teams are now simply ignoring many alerts, with a false sense of confidence because they have prioritized a few.
Bottom line: theoretical attacks don’t reflect real events. For example, a publicly exposed machine with a known vulnerability should have a specific risk associated with it, however if there is actual evidence that it is in the process of being exploited (i.e. an active APT or an incident), the priority should be much higher with immediate action taken. In most contexts, including security, theoretical assumptions are not enough to come to concrete conclusions.
Here’s a real-world example we recently encountered. A customer’s CI/CD automation server had been publicly exposed. An attacker successfully exploited a vulnerability in the exposed server and gained control over it. From there, the attacker was able to obtain access keys in AWS and used the keys to access multiple S3 buckets. This almost led to the exfiltration of a large amount of sensitive data.
The following activities were detected and correlated:
- Unusual activity time for ‘User CI/CD Server’
- Anomalous access – ‘User CI/CD Server’ invoked API calls from an unusual country & ISP and using an unusual user-agent
- Anomalous AWS usage activity – ‘User CI/CD Server’ made unusual API calls (list buckets, delete bucket)
- First usage of high-risk API calls – Delete bucket API was used for the first time
- Anomalous access to S3 buckets – ‘User CI/CD Server’ accessed S3 buckets in an unusual manner – buckets, number of buckets, operations and amount of accessed data
All the above were synthesized together into a single coherent alert. The customer was then able to manually apply mitigation steps, in this case, making sure the CI/CD server was no longer exposed and revoking and replacing the access keys. This saved the customer from a breach that would have resulted in exfiltrated data and could have cost the company thousands of dollars.
A posture management solution, even one with ‘toxic combinations’ would have notified the customer about the exposed server, possibly about the vulnerability it had (if it was already known and was discovered by the system), and even perhaps about the crown jewels in the S3 buckets. However, the toxic combination would not have received a high score since it involved standard web ports. Without runtime protection, the customer would not have been able to detect all of these during an ongoing exploit in real-time (let alone use the intelligence of this scenario being exploited in the wild) for security teams to prioritize and fix before the data exfiltration.
Posture management has turned into an exercise in prioritization, but this hasn’t made us safer. The key to change is runtime observability. Runtime threat detection is a new security concept that looks at network anomalies together with user and workload identity access management, to surface actual threats that need to be resolved immediately. This bridges the gap between having theoretical group of toxic combinations of misconfigurations and vulnerabilities to having awareness that those issues are being currently utilized to compromise your infrastructure.
So, does the tree falling make a sound? I guess we can leave that one to the philosophers. For those of us in security, those sounds are mostly immaterial. The next phase of cloud security is one in which runtime visibility is added on top of theoretical anomaly awareness, to gain a true picture of security posture.
If you would like to learn how to fight AI-based threats, with AI-based security, please register for our webinar!