This blog was written by Amir Shachar, Director, AI and Research.
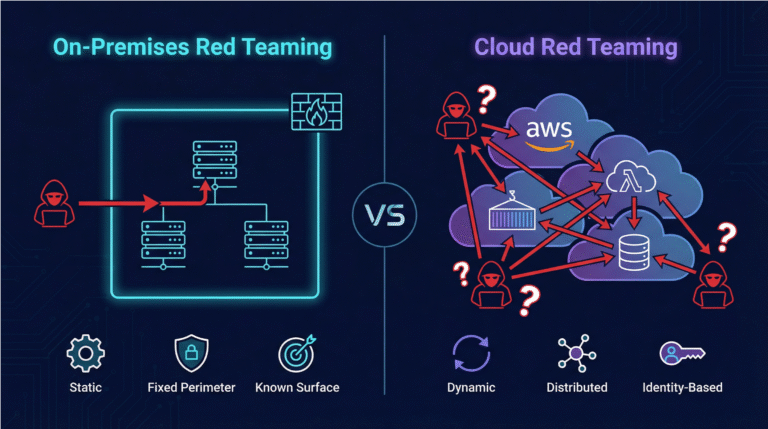
The digital landscape constantly evolves, increasing complexity to cloud security. In this dynamic environment, it’s becoming more and more challenging to pinpoint and assess the risks associated with cloud incidents, especially when the sequences in question straddle the line between malicious and benign intentions. Traditional methods often falter, unable to navigate this intricate tapestry with the precision and insight required.
However, at Skyhawk Security, we are pioneering a revolutionary approach to decipher this complexity. As the Director of AI and Security Research, I am thrilled to share our journey towards building a more secure digital future.
The Challenge of Assessing Cloud Incident Risks
The first layer of our narrative revolves around the inherent difficulty in assessing the risk associated with cloud incidents. Often, the sequences involved toe a fine line between malicious and benign activities, making it extremely difficult, even for seasoned professionals and traditional Machine Learning frameworks, to accurately judge activities and events as malicious or benign.

Image 1: An incident easily classified as benign.
Image 2: An incident easily classified as malicious

Image 3: An incident not easily as benign nor as malicious
The Evolution of LLMs as Security Analysts
To tackle this challenge, we are turning to Large Language Models (LLMs) to serve as vigilant security analysts. These AI professionals meticulously analyze the sequences, assigning scores based on their potential maliciousness. A single model, however, isn’t sufficiently equipped to tackle this task alone. Thus, we amalgamate the insights derived from multiple models, leveraging a majority voting system and a confidence level determined by the variance in their results to create a more robust security analysis framework.
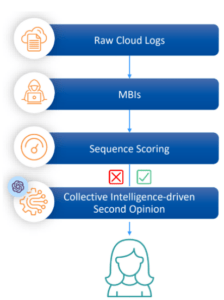
Image 4: Raw cloud logs are transformed into malicious behavior indicators, which are then correlated, scored, and augmented by AI agents, replacing the need for direct review by incident response (IR) professionals within traditional machine learning frameworks.
The Importance of Benchmarking LLMs
At this juncture, it’s vital to understand that not all LLMs are created equal. They come equipped with different capacities, capabilities, and perspectives on the world. Consequently, we embarked on a rigorous benchmarking process, evaluating the performance of various industry-leading LLMs such as GPT-4, Llama70b-chat, GPT-3.5, Google Bard, and Llama7b on ground truth sequences pre-labeled by our analysts. This benchmarking exercise enables us to rank the LLMs, creating a system that weighs their inputs in calculating the average votes, thereby refining the malicious classification process. It gives us more confidence in identifying threats to your cloud environment.
Image 5: Should all the LLMs scores be weighted equally, or should more proficient AI agents be given greater weight in the averaging process?
While this approach proves accurate, it has its drawbacks. For example, several different agents are supposed to provide an inference in real-time, and the combination of the agents’ classification seems arbitrary – relying on the wisdom of the crowd without hearing exactly what each of the voters had to say might miss the full picture.
Introducing the “Integrated Learning” Framework
Our journey doesn’t end here. Announcing a new comprehensive framework for ensemble modeling of LLMs. This initiative, designed to enhance the maliciousness classification process, seamlessly integrates the expertise of human security researchers with the analytical prowess of LLM-based AI agents. The framework consists of two dynamic components:
- “Sage” LLM: This primary model undergoes fine-tuning to absorb the analytical methodologies applied by human experts during manual labeling processes. This training equips it with the ability to discern the nuances of maliciousness classification.
- “Junior” LLM: These are the different LLMs tasked with classifying potential threats in new sequences, offering varied perspectives and insights.
Through supervised self-improvement with fine-tuning fed by Reflexion on a generalization of the results of the junior models, the “Sage” continually refines its understanding, learning from each classification decision made by the “Juniors.” It gets smarter and smarter, so predicting threats gets more and more accurate.
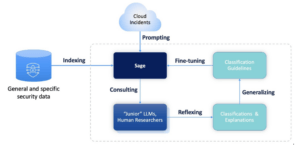
Image 6: A schematic diagram of the Integrated Learning framework
Benefits of Integrated Learning
This new framework promises several advantages over existing ML Ensemble frameworks like Bagging and Boosting, including:
- Improved Generalization: The ability to learn and adapt from the findings and mistakes of the “Junior” models, allowing for better predictive accuracy, especially in complex or noisy datasets.
- Model Interpretability: Offering a more precise, more understandable representation of the decision-making process.
- Robustness: A heightened resilience to outliers and adversarial attacks, minimizing overfitting and enhancing data quality management.
- Efficiency: Potentially offering computational advantages when dealing with large datasets or resource-constrained environments. The fact that we needn’t run each model separately (contrary to stacking and bagging) is an advantage.
- Flexibility: The ability to effectively incorporate various “Junior” models as well as human-driven insights, catering to different problem types.
- Incremental Learning: Facilitating continuous adaptation and refinement based on changing data distributions over time.
- Reduced Bias: A multi-faceted approach to reduce prediction bias, ensuring a more balanced and fair outcome.
As we venture forward, we are confident that this Integrated Learning framework not only outperforms each model but also significantly improves upon the simplistic ensemble frameworks based on average and variance evaluations.
Summary
In conclusion, I emphasize our unwavering commitment to fostering a more secure digital environment. The launch of this benchmark, highlighted at the Cloud Security Alliance’s SECtember conference, underlines our dedication to innovating with generative AI in the cloud security space. By bridging human insights with evolving AI technology, we aim to pioneer a future where security is guaranteed and promises upheld with unwavering confidence and cutting-edge technology.
We invite you to join us toward a safer and more secure digital future. If you would like to dive into the technical details, please see our post, “New Horizons in Cloud Security Part 2: Benchmarking and Novel Self-improving AI Framework for Maliciousness Classification Using Large Language Models”.