This blog was written by Amir Shachar, Director, AI and Research.
As we saw in Part 1 of this blog series, New Horizons in Cloud Security, the new approach to leveraging large language models was outlined. In this blog, we will dive into the technical details.
Logs as well as other telemetries (i.e. activity logs, network logs, etc.) from public cloud providers, like AWS, Google, and Azure, offer significant insights into identifying malicious behavior which can lead to the identification of threats. Identifying these threats early in the attack protects organizations from experiencing cloud breaches, which can damage a company’s brand, employees, or worse, their customers, create privacy violations as well as result in significant financial damage. Skyhawk Security’s data science team has conducted a maliciousness classification benchmark comparison of leading LLMs – ChatGPT, Google BARD, Claude, and LLAMA2-based open LLMs.
Through this research, Skyhawk has identified an enhanced classification process based on an innovative, self-improving AI Framework which leverages multiple LLMs. The framework’s accuracy is greatly improved in identifying threats, helping organizations achieve their security goal – to prevent cloud breaches.
Methodology for Benchmarking LLMs
Participants: ChatGPT, Google BARD, LLAMA2-based open LLMs
- Task: Determine the maliciousness level of aggregated sequences extracted from cloud logs (e.g., AWS logs).
- Evaluation Metric: Performance measured using precision, recall, and F1-score.
- Threshold: An optimal threshold is introduced to decide the classification outcome.
- Leaderboard: Evaluation results and rankings are accessible on Skyhawk’s website.
Results
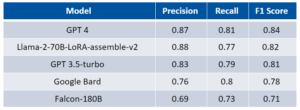
The results are based on a representative sample of 200 human-labeled sequences.
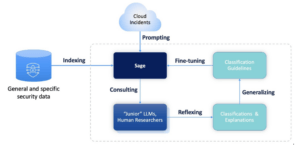
Introduction to the New AI Framework: “Integrated Learning”
Objective: Enhance the maliciousness classification process by combining human security researchers’ insights and self-improving LLM-based AI agents.
“Sage” LLM: Initially, a designated LLM is fine-tuned to learn the reasoning applied by human security experts in manual labeling processes. This equips it with an understanding of the intricacies of maliciousness determination.
“Junior” LLM: Distinct LLMs (“Juniors”) are employed for the actual classification of maliciousness in new sequences. We apply different LLMs each time to ensure we cover different angles and observations.
Supervised Self-improved Reflexion: The “Sage” component engages in supervised Reflexion on the maliciousness classification outcomes of the “Junior.” It learns and accumulates new perspectives and insights from each classification decision, self-improving its classification mechanism.
Benefits of “Integrated Learning”:
- Transfer Learning: The “Sage” LLM, trained with insights from human experts, becomes more adaptable across diverse clients and scenarios, resulting in heightened reliability for unseen sequence types.
- Holistic Approach: The combination of multiple LLMs and their mutual knowledge exchange enables a comprehensive analysis of maliciousness, encompassing a wider range of potential threats.
Illustration:
How is it different than other AI frameworks:
This “Integrated learning” approach can be viewed as another AI framework that combines multiple weak models (in this case, “Juniors”) into a single strong one (which we refer to as “Sage”). However, in some of the other ML frameworks, the strong model is either comprised of separate weak models (such as Boosting, Bagging and Stacking) that are glued together with the main framework (for example, by averaging in retrospect in Bagging), or where the weak models continuously improve on the mistakes of the previous ones (as in Boosting). Using such a framework in our case would require applying several models in real time – which might not be as scalable as running a single model. In other frameworks such as Active or Federated Learning, while the information from each model is propagated to the strong model, it is done in a not easily explainable fashion (e.g., in Federated Learning the gradients from each agent are accumulated into the main framework). One problem with all the frameworks mentioned above is that it is very hard to impossible to keep track on the changes in the strong model. Questions such as, which of the weak models caused this decision to be made by the strong model, or which insights were learned in each sub-engine, cannot be easily answered in retrospect, making it difficult to backtrace and debug.
In contrast, in Integrated Learning the insights learned by the Sage can be backtracked to each junior model, making it very easy to debug and understand the entire training process. Still, they are integrated naturally into the strong model with fine-tuning, making it possible to prompt a single query to the Sage and not reflect on many other models in real-time. It also renders any inference in real time easily and fully explainable with a simple query on the log of the fine-tuning. Another advantage of Integrated Learning is the ability to naturally integrate insights from human subject matter experts.
Conclusion
In conclusion, benchmarking prominent LLMs for maliciousness classification is foundational in enhancing cybersecurity. The innovative AI framework capitalizes on human-like reasoning processes to facilitate accurate and evolving classification. This synergy of advanced technology and strategic insight empowers organizations to better safeguard their digital ecosystems against emerging threats to achieve their goal of preventing cloud breaches.